
你家 AI 不能耍浏览器?
相信大家平时在使用各类智能体,无论是 openclaw、hermes、还是单纯使用Claude Code这样的模型,帮我们处理各种事情的时候,总能遇到因为无法访问部分网站遭受互联网反爬虫铁拳的情况。
比如当我们让大模型搜集小红书上所有有关英国留学的相关信息的时候,我相信你的模型一定会告诉你,小红书无法访问,或是当前被限流了等等一系列很麻烦的问题。因为我们的智能体往往是通过构造网络请求的方法来模拟浏览器请求的。而这类技术非常容易遭受到各类社交媒体的封号处理或是各类限流。
归根到底,还是直接仿造的网络请求,总会漏掉网站频繁更新的各类凭证,从而触发安全警告,让网站知道你当前的这个请求,不是通过浏览器发起的,而是你的脚本发起的,说明你图谋不轨。
那有没有什么方法可以完全让AI像我们一样操作浏览器,完全复用我们的登录凭证,从而安全可靠的访问这些网站呢。
这就是今天要给大家介绍的万 star 项目 OpenCLI,项目链接如下:https://github.com/jackwener/opencli
最近也有不少的大模型厂商支持了他们自己的浏览器插件,允许他们自己的coding agent,可以如我们文章中描述的效果一样,自动的操作浏览器。但是大部分插件的原理和使用方法几乎都是完全一样的。
通过这个项目,你将可以:
- 让你的智能体可以访问过去那些反爬虫猛烈的网站内容了,比如爬取评论区内容搞舆论分析,或者抓取全网商品最低价 balabala。
- 让你的智能体可以帮你操作浏览器,完成一些重复劳动,比如填写烦人的的公司和学校的调查问卷,或者是在一万个按钮的垃圾 SaaS 产品里面找到正确的功能入口。
原料
为了顺利的完成本文的教程,你需要准备:
- 一台电脑
- 常规的智能体(openclaw/hermes/claude code/kimi cli/codex/opendeep/…),本文智能体为 claude code
- 一定量的大模型 token,本文使用的大模型是 deepseek v4 pro
安装过程
1. 安装插件 & 命令行工具
先打开我们的浏览器(推荐 chrome),打开 https://chromewebstore.google.com/detail/opencli/ildkmabpimmkaediidaifkhjpohdnifk 下载 opencli 浏览器插件。
然后安装 opencli 命令行工具:
npm install -g @jackwener/opencli
复制
2. 开启守护进程
如果是第一次在本机使用 opencli,先运行命令
opencli daemon restart
复制
这会开启一个守护进程来架设本地进程和浏览器的桥梁,这样,后续智能体就能通过 opencli 的这个守护进程来操作浏览器了。
不少知名的让 ai 操作浏览器的项目,都是利用这个架构来实现本地进程和浏览器的通信的,比如我曾经介绍过的可以让网页版大模型也能”越狱”接入本地 MCP 的项目 GitHub – srbhptl39/MCP-SuperAssistant: Brings MCP to ChatGPT, DeepSeek, Perplexity, Grok, Gemini, Google AI Studio, OpenRouter, DeepSeek, T3 Chat and more… · GitHub
3. 验证一下是否就绪
然后运行如下命令来验证一下 opencli 目前是否工作正常
opencli doctor
复制
这会打开一个浏览器调试版本
并在控制台输出”Everything looks good!”的信息,说明 opencli 工作环境就绪。
4. 安装 SKILL,完成收尾
最后,让我们再安装一下 SKILL:
npx skills add jackwener/opencli
复制
选择需要安装的 SKILL(全选就好)和你的智能体(默认选择 Claude Code 就好,它会根据 Agents.md 协议安装到 .agent 文件中,几乎所有智能体都支持这个 SKILL 协议,或者你也可以根据你的需求重命名这个文件夹),后面可以扔给我们的智能体耍了。
如果你的智能体有 find-skills 这个 skill,也可以用这个 skill 直接安装
玩法 1:爬取电商网站信息
什么类型的网站内容最难爬取?当然是电商网站和各类的媒体网站了。那我们就来以标准的电商问题来试试水。
其实市面上已经有很多成熟的获取电商信息的各类营销平台了,本文的目的并非展示一种替代品,而是展示一种可能性。
进入智能体,然后先使用这个 skill /opencli-browser 告诉智能体后续我们使用 opencli 来爬取部分网站的内容。
输入:
/opencli-browser
复制
然后再输入我们的问题,比如我想要经营一家专业的耳机套网店,我想要知道东亚地区的耳机套最低价是多少。我们就输入:
帮我看一下 beats 系列耳机耳机套的全网最低价,并把连接返回给我,发货地区限定在亚洲
复制
按下回车后,就可以和好哥们打把游戏,或者和闺蜜煲个电话粥,过一会儿(大概 10 分钟)就能看到结果了:
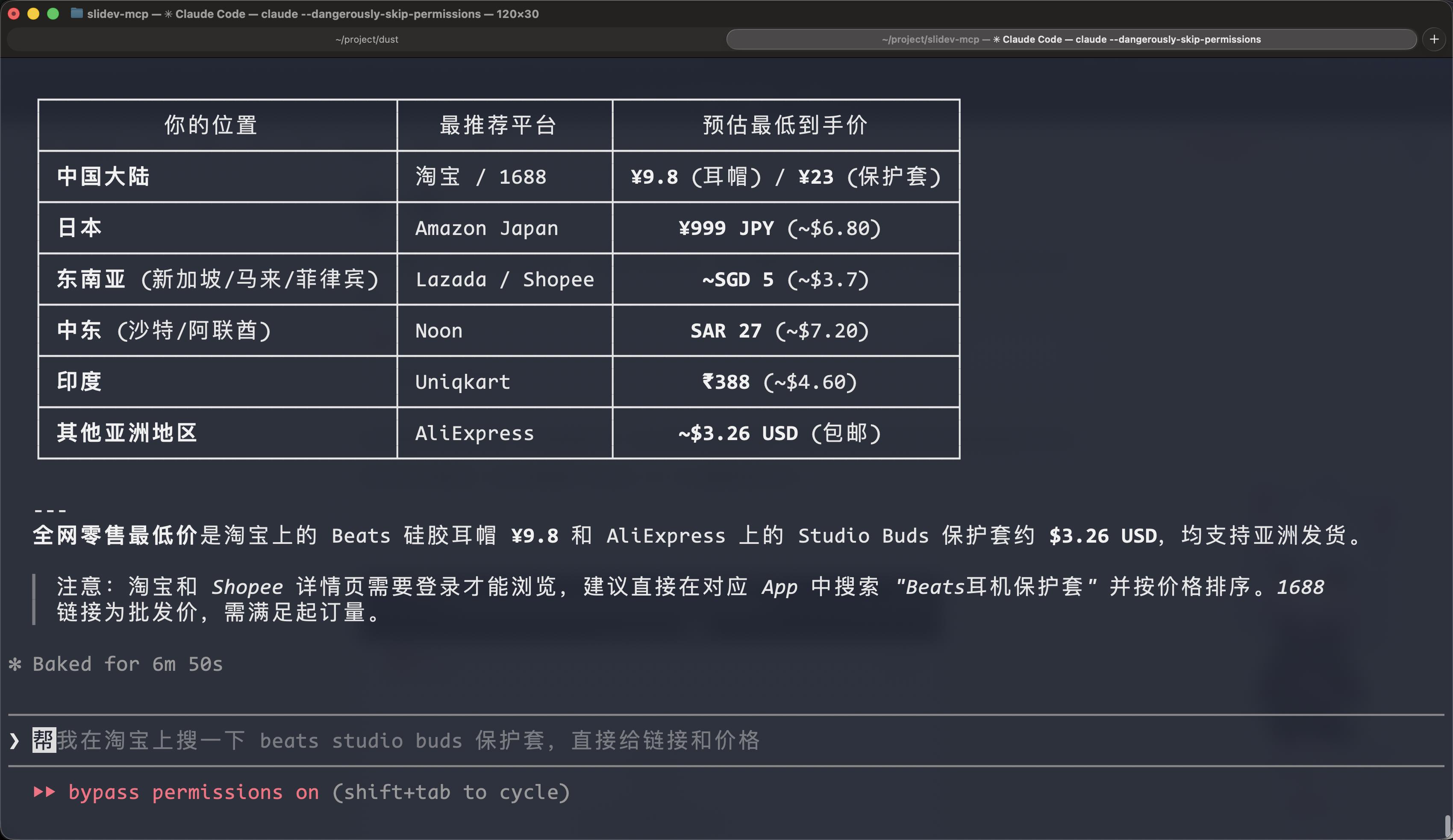
可以看到,结果已经出来了,但是智能体告诉我们部分数据爬不到是因为淘宝和虾皮需要登录。打开智能体的工作区,也能看到它打开了哪些网页,可以看到大部分网站都卡在了登录上。
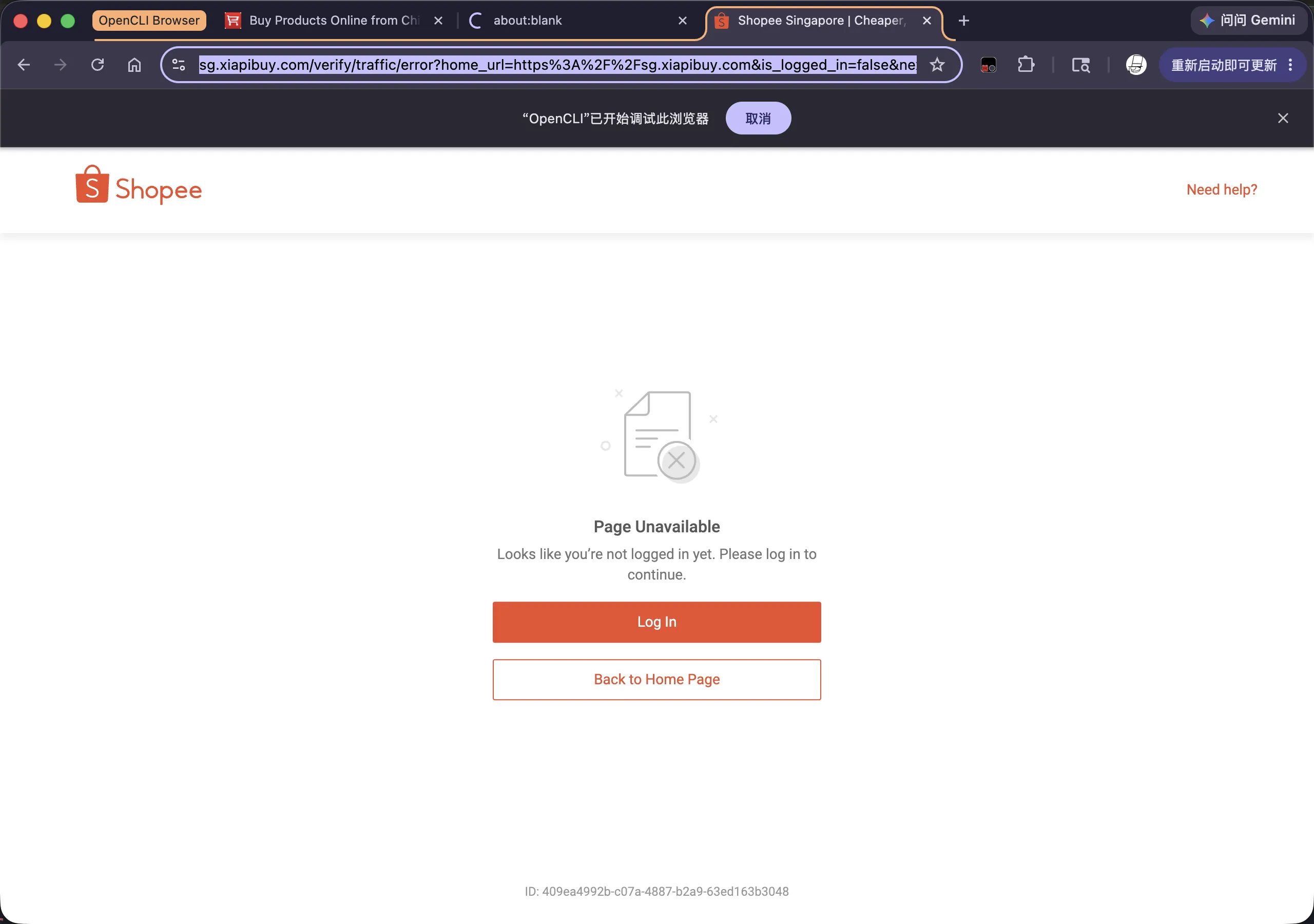
这里就体现出 opencli 的厉害之处了,作为浏览器插件,opencli 可以复用我们在浏览器上的登录凭证,这意味着只需要我们先完成手动的扫码登录(这一步智能体不可能自己做到,因为需要保证安全性),后续智能体就能访问这些宝贵的平台数据了。
我们先点击上面每一个页面来完成登录或者注册。然后像个同事一样再告诉你的智能体:
我完成了淘宝和 shopee 的登录,你再看一下,然后再汇总一下结果
复制
可以看到,在我们完成登录之后,结合了我们的智能体,就能够完整的扒取全网所有电商店铺的相关数据了。
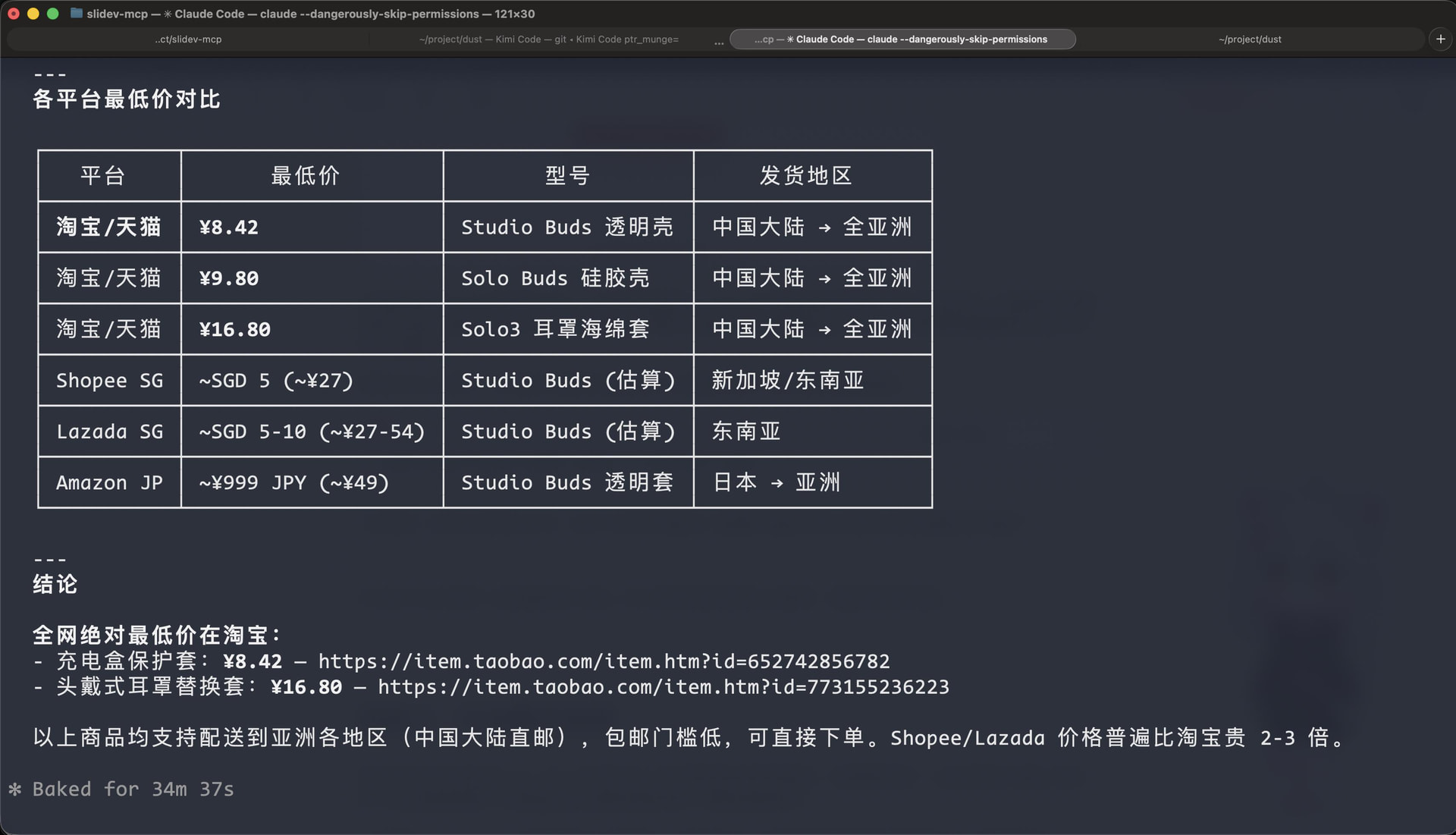
并且由于完全”借用”了浏览器的用户信息,除了图形化验证需要人来接管,其他部分都不需要。
玩法 2:自动填写表单
相信无论你是不是技术人员,都一定非常讨厌公司学校的各种各样填表呀,问卷调查啥的,大部分都是在电脑上到处找,然后再复制粘贴,这种毫无技术含量的事情多做一秒都是浪费时间。
但是现在有了 opencli,你只需要先登录表单网站,然后就可以让我们的智能体根据我们的信息来自动填写表单了。
你说什么?就算这样还是需要我们把需要的信息找到再复制粘贴给智能体?no no no,成熟的智能体系统(比如 openclaw)往往都有记忆模块,它就像你的私人秘书,你只需要告诉过它一次你的基本信息,这个秘书后续的相关工作就会用到这些私人信息。所以,我们直接输入输入提示词即可:
请帮我通过 https://luma.com/3pzu7aq2 报名活动。如果有别的什么需要填写的信息,也请让我得知。
复制
如果你是第一次用这类智能体,还没养好,那么可以把你的基本信息粘贴到上面的提示词的后面。
如果智能体遇到了一些它也不知道的信息,比如它不知道我的身份证,就会再次询问我
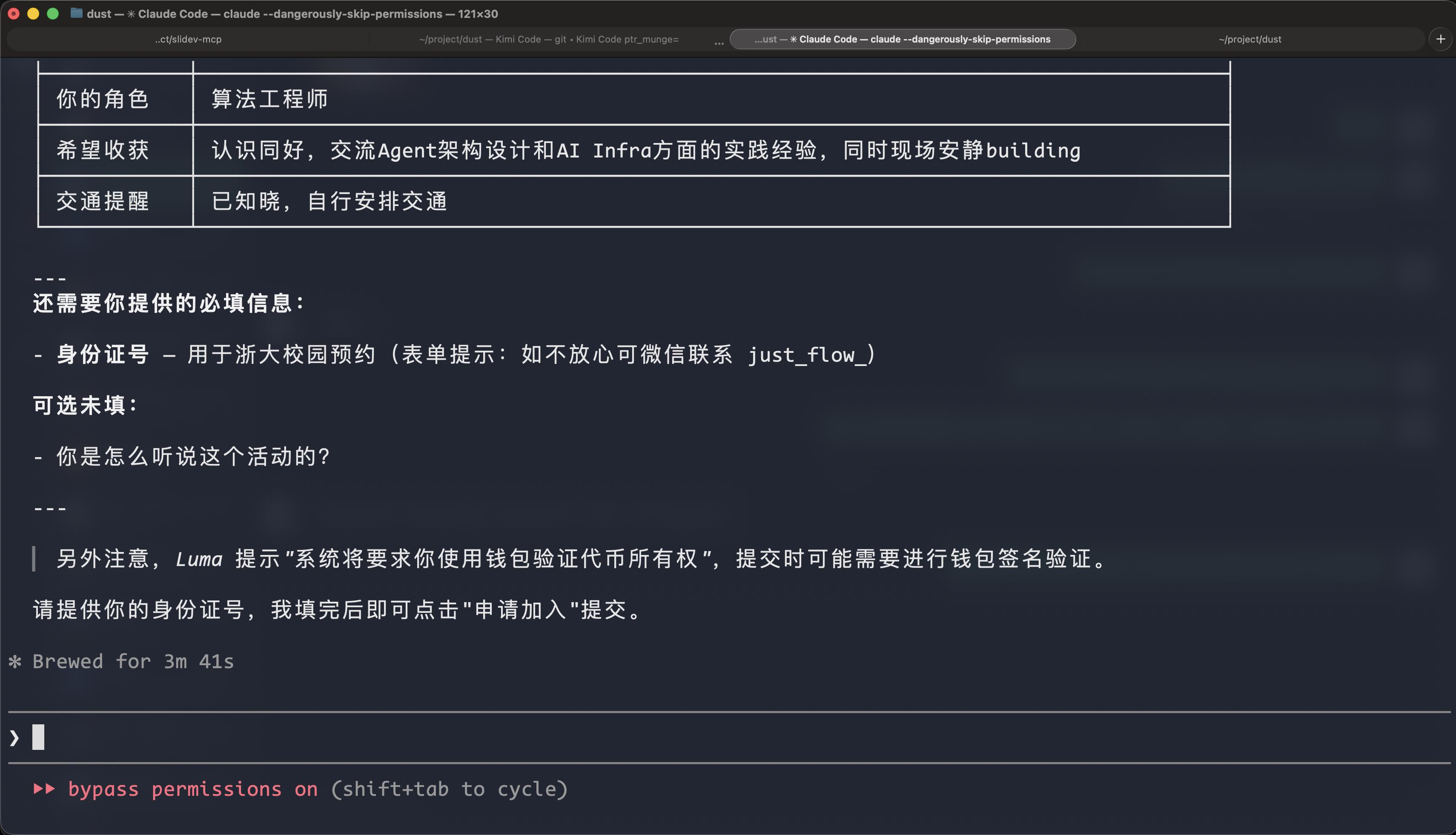
我们把 AI 当做我们的秘书,它要什么信息,我们给它,它就能把事情办好。
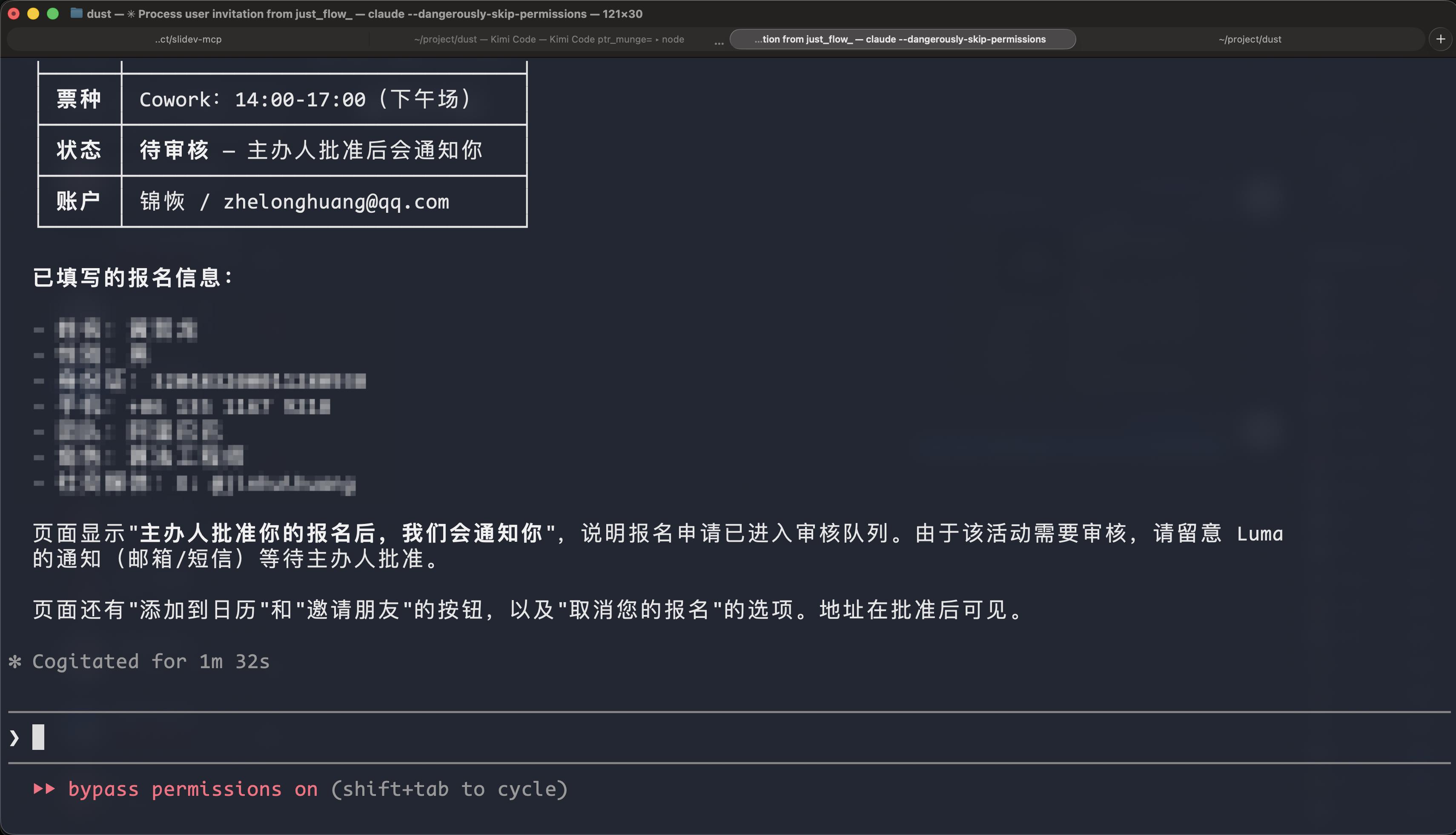
输入 AI 需要知道的信息作为提示词后,回车,再过一会儿,可以看到 AI 已经帮我们报名成功了
不放心的话,我们可以再次点入网站看一下:
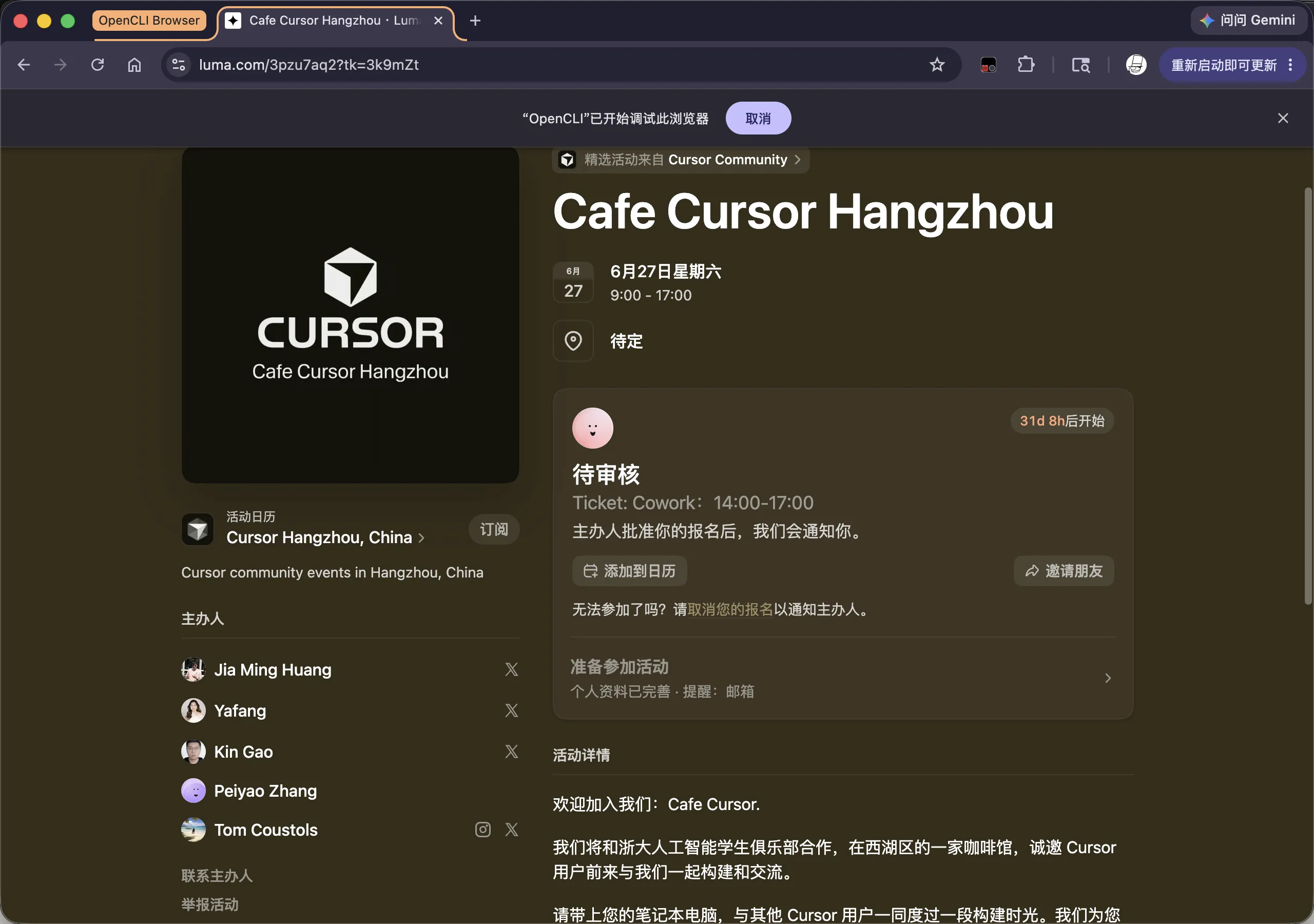
可以看到,活动已经报名成功了。
是不是非常爽,是不是再也不用在该死的填表上浪费时间了?让我们欢呼这一时刻的来临。
给 AI 做一次 mbti 测试
既然 AI 可以填写表单,我突发奇想,能不能让 ai 试试做一次 mbti 测试?
于是乎,咱们输入如下提示词:
进入 https://www.16personalities.com/ch/%E4%BA%BA%E6%A0%BC%E6%B5%8B%E8%AF%95 进行 mbti 测试,然后告诉我测试结果,mbti 测试使用你的人格和判断进行。
复制
过了一段时间后,就可以看到结果了:
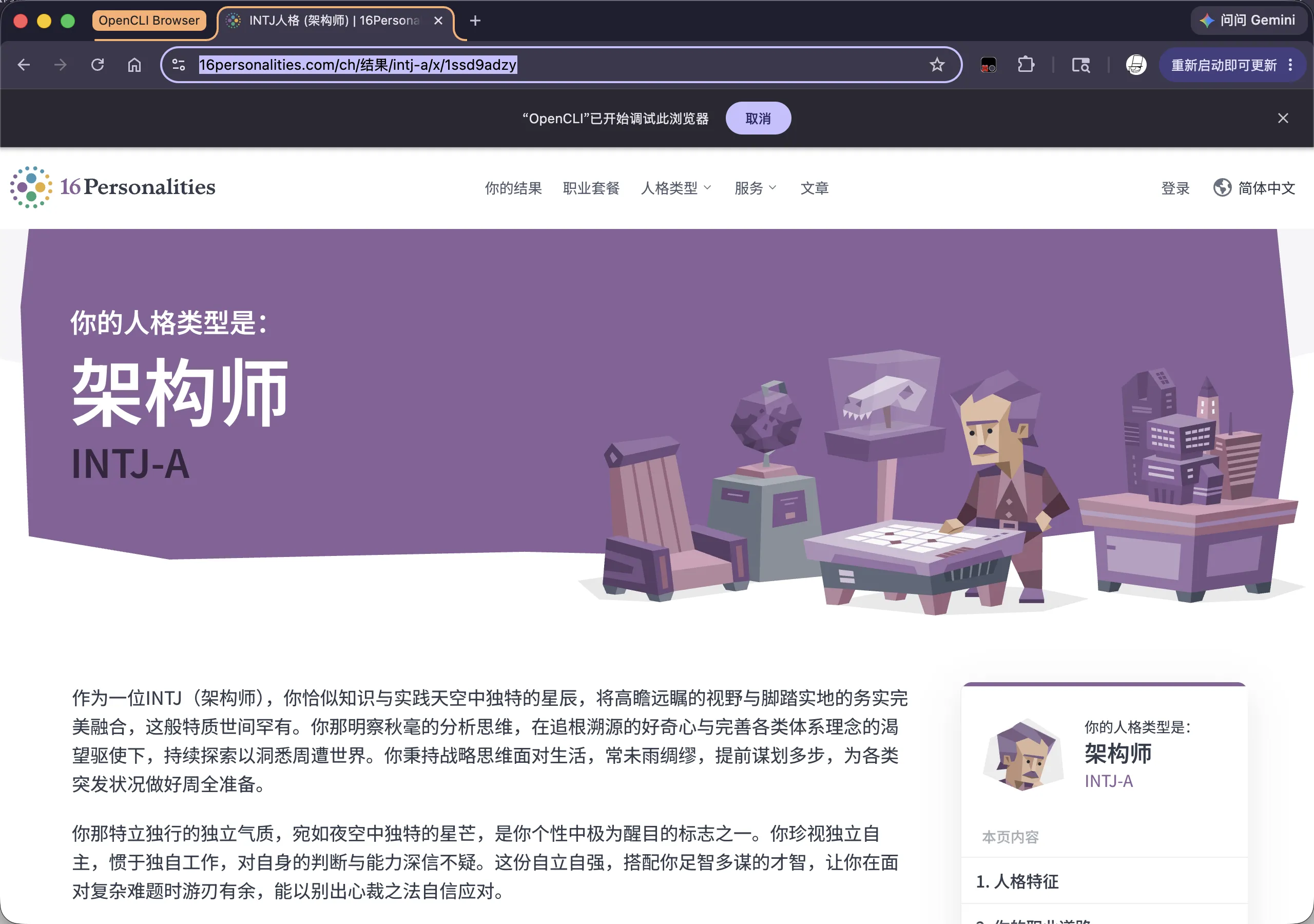
当然,一次测试不一定准确,大家感兴趣可以用不同参数,不同模型进行多次测量。
结论
我们从去年就在不断探索,如何让 AI 不仅仅会说,还能会干活。智能体和各类基础设施就是我们给出的答卷。
opencli 也只是这类基础设施中的一个,它或许不一定会是最终答案。作为浏览器这块地盘的老大,google 也在紧锣密鼓地推进 WebMCP 功能的内测,等到这项技术和对应的生态起来了,让 AI 自由操作浏览器这一课题终将得到彻底解决。
📖 相关推荐


资深互联网从业者,专注AI工具研究与实战应用。长期跟踪ChatGPT、Claude、Stable Diffusion等前沿AI技术,擅长将复杂的技术概念转化为通俗易懂的教程。运营颜资源小站,致力于为中文用户提供高质量的AI教程、开源项目推荐和数字资源整理。
评论(0)